Encoding psychology example
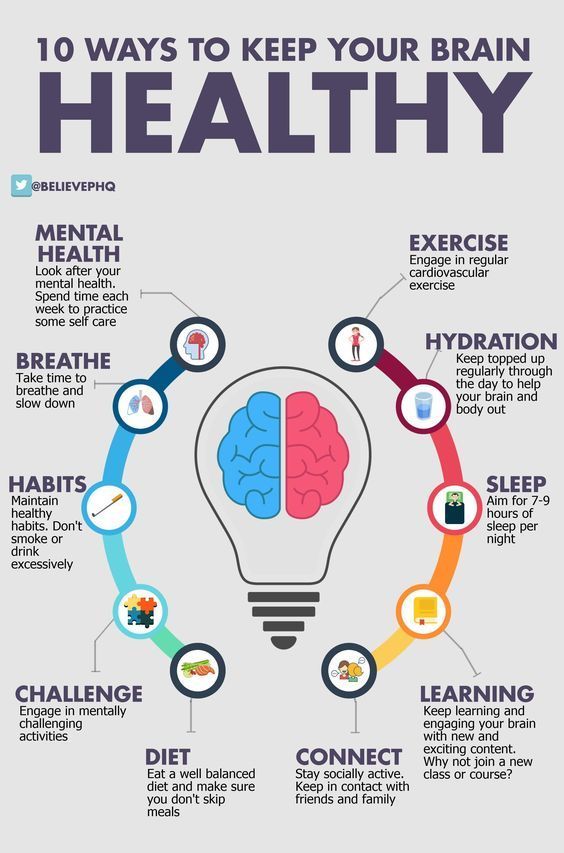
Memory Stages: Encoding Storage and Retrieval
“Memory is the process of maintaining information over time.” (Matlin, 2005)
“Memory is the means by which we draw on our past experiences in order to use this information in the present’ (Sternberg, 1999).
Memory is the term given to the structures and processes involved in the storage and subsequent retrieval of information.
Memory is essential to all our lives. Without a memory of the past, we cannot operate in the present or think about the future. We would not be able to remember what we did yesterday, what we have done today, or what we plan to do tomorrow. Without memory, we could not learn anything.
Memory is involved in processing vast amounts of information. This information takes many different forms, e.g., images, sounds, or meaning.
For psychologists, the term memory covers three important aspects of information processing:
In This Article
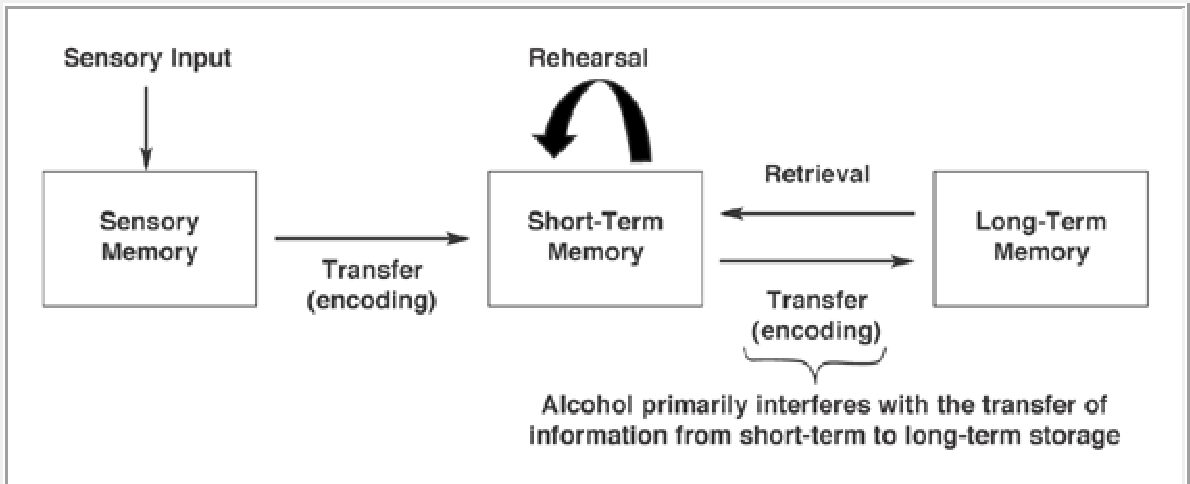
Memory Encoding
When information comes into our memory system (from sensory input), it needs to be changed into a form that the system can cope with so that it can be stored.
Think of this as similar to changing your money into a different currency when you travel from one country to another. For example, a word that is seen (in a book) may be stored if it is changed (encoded) into a sound or a meaning (i.e., semantic processing).
There are three main ways in which information can be encoded (changed):
1. Visual (picture)
2. Acoustic (sound)
3. Semantic (meaning)
For example, how do you remember a telephone number you have looked up in the phone book? If you can see it, then you are using visual coding, but if you are repeating it to yourself, you are using acoustic coding (by sound).
Evidence suggests that this is the principle coding system in short-term memory (STM) is acoustic coding. When a person is presented with a list of numbers and letters, they will try to hold them in STM by rehearsing them (verbally).
Rehearsal is a verbal process regardless of whether the list of items is presented acoustically (someone reads them out), or visually (on a sheet of paper).
The principle encoding system in long-term memory (LTM) appears to be semantic coding (by meaning). However, information in LTM can also be coded both visually and acoustically.
Memory Storage
This concerns the nature of memory stores, i.e., where the information is stored, how long the memory lasts (duration), how much can be stored at any time (capacity) and what kind of information is held.
The way we store information affects the way we retrieve it. There has been a significant amount of research regarding the differences between Short Term Memory (STM ) and Long Term Memory (LTM).
Most adults can store between 5 and 9 items in their short-term memory. Miller (1956) put this idea forward, and he called it the magic number 7. He thought that short-term memory capacity was 7 (plus or minus 2) items because it only had a certain number of “slots” in which items could be stored.
However, Miller didn’t specify the amount of information that can be held in each slot.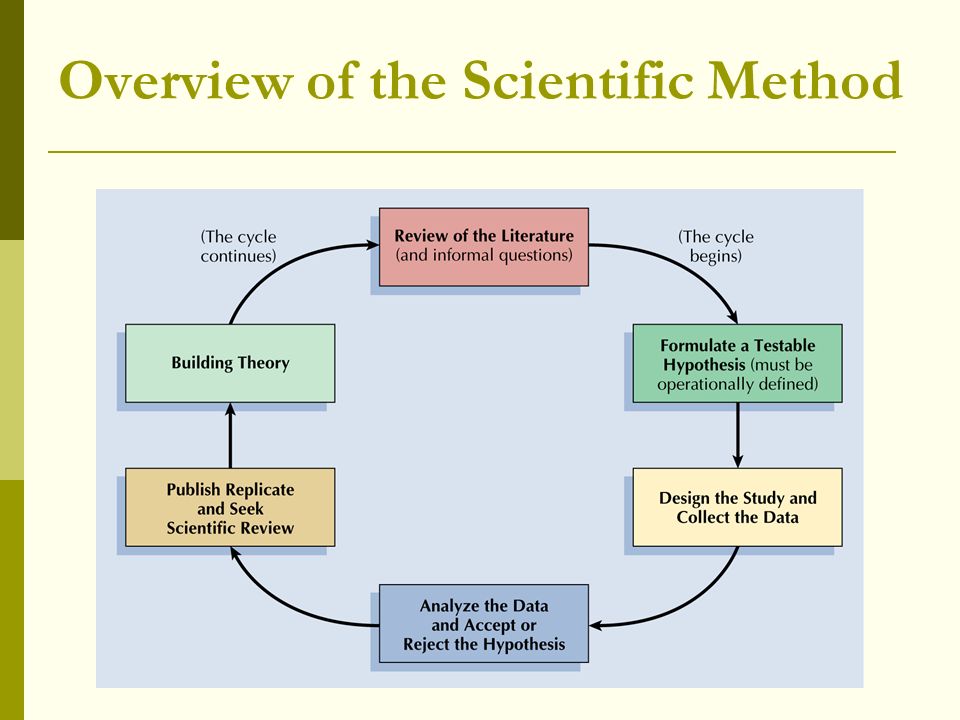 Indeed, if we can “chunk” information together, we can store a lot more information in our short-term memory. In contrast, the capacity of LTM is thought to be unlimited.
Indeed, if we can “chunk” information together, we can store a lot more information in our short-term memory. In contrast, the capacity of LTM is thought to be unlimited.
Information can only be stored for a brief duration in STM (0-30 seconds), but LTM can last a lifetime.
Memory Retrieval
This refers to getting information out of storage. If we can’t remember something, it may be because we are unable to retrieve it. When we are asked to retrieve something from memory, the differences between STM and LTM become very clear.
STM is stored and retrieved sequentially. For example, if a group of participants is given a list of words to remember and then asked to recall the fourth word on the list, participants go through the list in the order they heard it in order to retrieve the information.
LTM is stored and retrieved by association. This is why you can remember what you went upstairs for if you go back to the room where you first thought about it.:max_bytes(150000):strip_icc()/what-is-a-fixation-2795188_color-6b6fccdd74a64ad1bb660e352a0a21d9.gif)
Organizing information can help aid retrieval. You can organize information in sequences (such as alphabetically, by size, or by time). Imagine a patient being discharged from a hospital whose treatment involved taking various pills at various times, changing their dressing, and doing exercises.
If the doctor gives these instructions in the order that they must be carried out throughout the day (i.e., in the sequence of time), this will help the patient remember them.
Criticisms of Memory Experiments
A large part of the research on memory is based on experiments conducted in laboratories. Those who take part in the experiments – the participants – are asked to perform tasks such as recalling lists of words and numbers.
Both the setting – the laboratory – and the tasks are a long way from everyday life. In many cases, the setting is artificial, and the tasks are fairly meaningless. Does this matter?
Psychologists use the term ecological validity to refer to the extent to which the findings of research studies can be generalized to other settings. An experiment has high ecological validity if its findings can be generalized, that is, applied or extended to settings outside the laboratory.
An experiment has high ecological validity if its findings can be generalized, that is, applied or extended to settings outside the laboratory.
It is often assumed that if an experiment is realistic or true-to-life, then there is a greater likelihood that its findings can be generalized. If it is not realistic (if the laboratory setting and the tasks are artificial) then there is less likelihood that the findings can be generalized. In this case, the experiment will have low ecological validity.
Many experiments designed to investigate memory have been criticized for having low ecological validity. First, the laboratory is an artificial situation. People are removed from their normal social settings and asked to take part in a psychological experiment.
They are directed by an “experimenter” and may be placed in the company of complete strangers. For many people, this is a brand new experience, far removed from their everyday lives. Will this setting affect their actions? Will they behave normally?
He was especially interested in the characteristics of people whom he considered to have achieved their potential as individuals.
Often, the tasks participants are asked to perform can appear artificial and meaningless. Few, if any, people would attempt to memorize and recall a list of unconnected words in their daily lives. And it is not clear how tasks such as this relate to the use of memory in everyday life.
The artificiality of many experiments has led some researchers to question whether their findings can be generalized to real life. As a result, many memory experiments have been criticized for having low ecological validity.
ReferencesMatlin, M. W. (2005). Cognition. Crawfordsville: John Wiley & Sons, Inc.
Miller, G. A. (1956). The magical number seven, plus or minus two: Some limits on our capacity for processing information. Psychological Review, 63 (2): 81–97.
Sternberg, R. J. (1999). Cognitive psychology (2 nd ed.). Fort Worth, TX: Harcourt Brace College Publishers.
Long-Term Memory in Psychology: Types, Capacity & Duration
By
Saul Mcleod, PhD
Updated on
Updated on
Saul Mcleod, PhD
Educator, Researcher
BSc (Hons) Psychology, MRes, PhD, University of Manchester
Saul Mcleod, Ph. D., is a qualified psychology teacher with over 18 years experience of working in further and higher education.
D., is a qualified psychology teacher with over 18 years experience of working in further and higher education.
Learn about our Editorial Process
Reviewed by
Olivia Guy-Evans
Olivia Guy-Evans
Associate Editor for Simply Psychology
BSc (Hons), Psychology, MSc, Psychology of Education
Olivia Guy-Evans is a writer and associate editor for Simply Psychology. She has previously worked in healthcare and educational sectors.
Learn about our Editorial Process
Long-term memory (LTM) is the final stage of the multi-store memory model proposed by Atkinson-Shiffrin, providing the lasting retention of information and skills.
Theoretically, the capacity of long-term memory could be unlimited, the main constraint on recall being accessibility rather than availability.
Duration might be a few minutes or a lifetime. Suggested encoding modes are semantic (meaning) and visual (pictorial) in the main but can be acoustic also.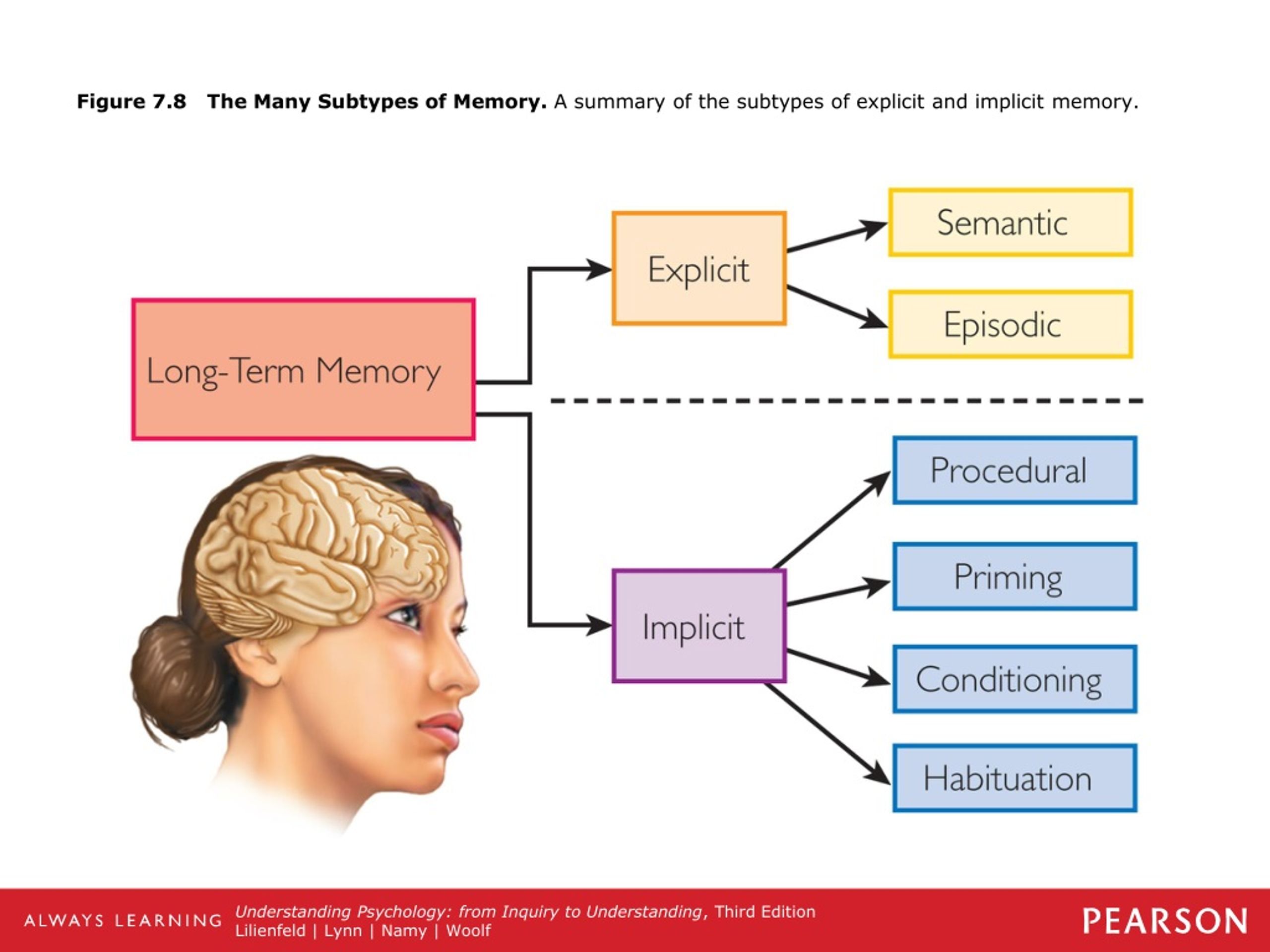
Using the computer analogy, the information in your LTM would be like the information you have saved on the hard drive. It isn’t there on your desktop (your short-term memory), but you can pull up this information when you want it, at least most of the time.
Types of Long-Term Memory
Long-term memory is not a single store and is divided into two types: explicit (knowing that) and implicit (knowing how).
One of the earliest and most influential distinctions of long-term memory was proposed by Tulving (1972). He proposed a distinction between episodic, semantic, and procedural memory.
Procedural Memory
Procedural memory is a part of the implicit long-term memory responsible for knowing how to do things, i.e., memory of motor skills.
It does not involve conscious (i.e., it’s unconscious-automatic) thought and is not declarative. For example, procedural memory would involve knowledge of how to ride a bicycle.
Semantic Memory
Semantic memory is a part of the explicit long-term memory responsible for storing information about the world. This includes knowledge about the meaning of words, as well as general knowledge.
This includes knowledge about the meaning of words, as well as general knowledge.
For example, London is the capital of England. It involves conscious thought and is declarative.
The knowledge that we hold in semantic memory focuses on “knowing that” something is the case (i.e. declarative). For example, we might have a semantic memory for knowing that Paris is the capital of France.
Episodic Memory
Episodic memory is a part of the explicit long-term memory responsible for storing information about events (i.e. episodes) that we have experienced in our lives.
It involves conscious thought and is declarative. An example would be a memory of our 1st day at school.
The knowledge that we hold in episodic memory focuses on “knowing that” something is the case (i.e. declarative). For example, we might have an episodic memory of knowing that we caught the bus to college today.
Cohen and Squire (1980) drew a distinction between declarative knowledge and procedural knowledge.
Procedural knowledge involves “knowing how” to do things. It included skills, such as “knowing how” to playing the piano, ride a bike; tie your shoes, and other motor skills.
It does not involve conscious thought (i.e. it’s unconscious – automatic). For example, we brush our teeth with little or no awareness of the skills involved.
Declarative knowledge involves “knowing that”, for example London is the capital of England, zebras are animals, your mum’s birthday etc.
Recalling information from declarative memory involves some degree of conscious effort – information is consciously brought to mind and “declared”.
Evidence for the distinction between declarative and procedural memory has come from research on patients with amnesia. Typically, amnesic patients have great difficulty retaining episodic and semantic information following the onset of amnesia.
Their memory for events and knowledge acquired before the onset of the condition tends to remain intact, but they can’t store new episodic or semantic memories.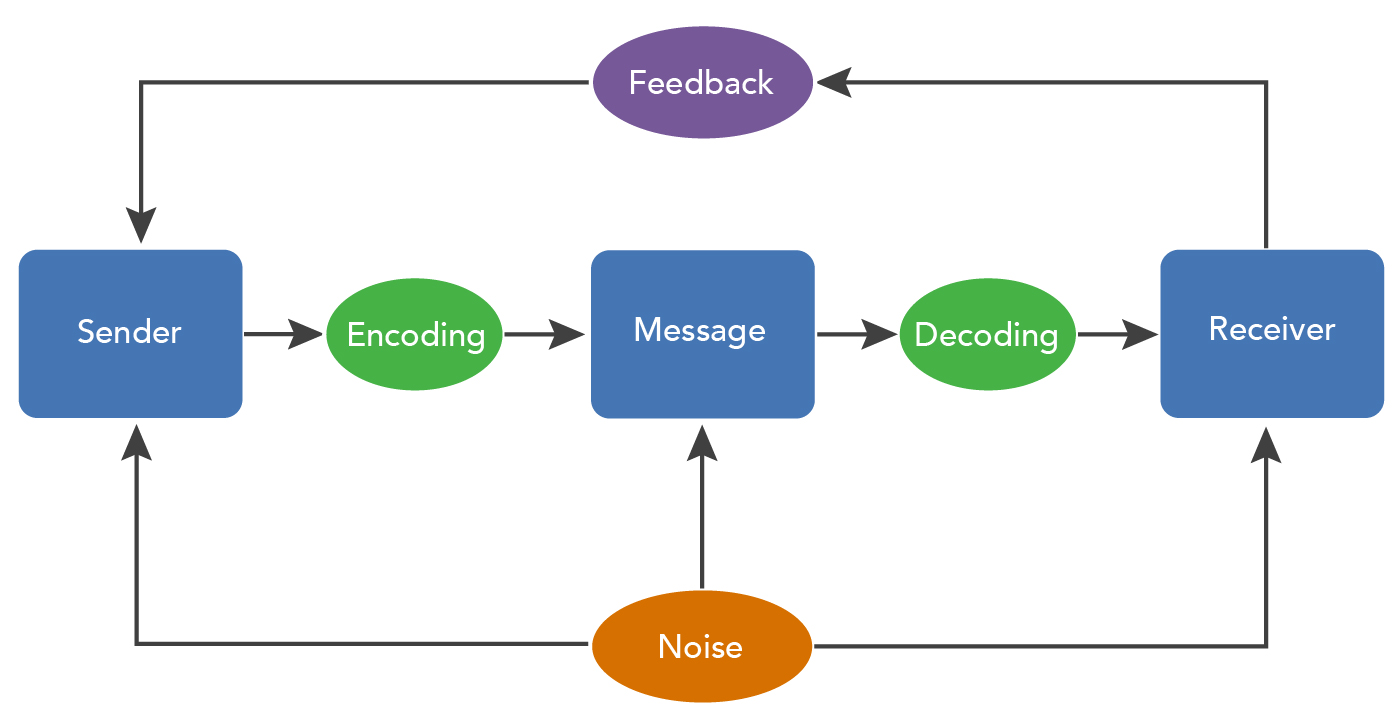 In other words, it appears that their ability to retain declarative information is impaired.
In other words, it appears that their ability to retain declarative information is impaired.
However, their procedural memory appears to be largely unaffected. They can recall skills they have already learned (e.g. riding a bike) and acquire new skills (e.g. learning to drive).
Very Long-Term Memory Experiment
Bahrick, Bahrick, and Wittinger (1975) investigated what they called very long-term memory (VLTM). Nearly 400 participants aged 17 – 74 were tested.
Participants were asked to list the names they could remember of those in their graduating class in a free recall test.
There were various conditions including: a free recall test, where participants tried to remember names of people in a graduate class; a photo recognition test, consisting of 50 pictures; a name recognition test for ex-school friends.
Results of the study showed that participants who were tested within 15 years of graduation were about 90% accurate in identifying names and faces. After 48 years they were accurate 80% for verbal and 70% visual.
After 48 years they were accurate 80% for verbal and 70% visual.
Participants were better at photo recognition than free recall. Free recall was worse. After 15 years it was 60% and after 48 years it was 30% accurate.
They concluded that long-term memory has a potentially unlimited duration.
A strength of this study s that it used meaningful stimuli. Bahrick et al. tested people’s memories from their own lives by using high school yearbooks. The study has higher external validity when compared to studies using meaningless pictures (where recall rates tend to be lower).
But the study did not control for confounding variables (they may have rehearsed their memory of the photos over the years), so any real-world application should be applied with caution.
References
Bahrick, H. P., Bahrick, P. O., & Wittinger, R. P. (1975). Fifty years of memory for names and faces: a cross-sectional approach. Journal of Experimental Psychology: General, 104, 54-75.
Cohen, N. J., & Squire, L. R. (1980). Preserved learning and retention of pattern analyzing skill in amnesia: Dissociation of knowing how and knowing that. Science, 210, 207–209.
Tulving, E. (1972). Episodic and semantic memory. In E. Tulving & W. Donaldson (Eds.), Organization of Memory, (pp. 381–403). New York: Academic Press.
Olivia Guy-Evans
BSc (Hons), Psychology, MSc, Psychology of Education
Associate Editor for Simply Psychology
Olivia Guy-Evans is a writer and associate editor for Simply Psychology. She has previously worked in healthcare and educational sectors.
Saul Mcleod, PhD
Educator, Researcher
BSc (Hons) Psychology, MRes, PhD, University of Manchester
Saul Mcleod, Ph.D., is a qualified psychology teacher with over 18 years experience of working in further and higher education.
What is “information coding” in psychology
Definition 1 In psychology information coding is its correlation with a certain set of conventional signs, that is, with a certain code.
The information to be transmitted to the operator is presented as a means of display in the form of this code, which the operator needs to read and then decode. It is because of this that the choice of the optimal code is the main task in the design of the information environment. The code that is able to provide maximum speed, as well as reliability of reading and further processing of information, is considered optimal. For different systems, different tasks and different information, their codes are optimal.
Distinguishing alphabets by features
Coding is based on the use of a basic set of conventional characters - the alphabet. Alphabets can be distinguished by several features, including:
- Modality. This is the relation of signs to a specific type of sensation.
- Category. It is a certain aspect of sensation within a modality.
- Length. This is the number of gradations, that is, the number of characters in the alphabet.
- Abstract. Signs can either have an explicit referent, or be associated with it purely conditionally.
Alphabets are also characterized by dimensionality (the number of characters), as well as the principles of arrangement of composite characters.
Selecting a specific modality
The choice of modality is determined by the characteristics of the information being encoded, as well as the context in which the system will be used. In most cases, such a coding method as visual data coding is chosen. To unload the operator's visual system, sound and/or vibrotactile signals are used. Non-visual modalities are also used in those cases when they are the most natural for displaying the necessary information. Auditory modality, for example, can be used to convey data regarding temporal trends, since it is the individual's auditory system that has very high temporal resolution. Auditory and tactile signals are often used to signal infrequent but important events. In such a case, the use of visual representation would be absolutely ineffective.
In such a case, the use of visual representation would be absolutely ineffective.
Within a particular modality, there are different ways to encode different features. For example, for a visual modality, the displayed value can be encoded by categories such as color, shape, brightness, orientation, size. Shape and color coding is often preferred over other types of coding. For example, these types of coding make possible the maximum speed of visual search and recognition of any characters. Brightness coding can be called a negative example - given the variability of perceptual conditions, the operator can distinguish with sufficient reliability only a couple of gradations of a given feature (dim-bright).
Note 1Size coding is also not always considered successful - even when using three size gradations, the operator can make systematic errors when reading the size of specific objects.
A significant visual type of encoding is the use of alphanumeric alphabets. They can be used to transfer significant amounts of heterogeneous information, thereby providing a sufficiently high speed, as well as reliability of reading information. A large number of studies have been devoted to the analysis of the optimal form of signs of this type. The ease of reading alphanumeric characters directly depends on a large number of conditions - for example, font, line thickness, height-to-width ratio of characters, and so on. The most general requirement is that the apparent size of such signs should not be less than fifteen to thirty arc minutes.
They can be used to transfer significant amounts of heterogeneous information, thereby providing a sufficiently high speed, as well as reliability of reading information. A large number of studies have been devoted to the analysis of the optimal form of signs of this type. The ease of reading alphanumeric characters directly depends on a large number of conditions - for example, font, line thickness, height-to-width ratio of characters, and so on. The most general requirement is that the apparent size of such signs should not be less than fifteen to thirty arc minutes.
More difficult questions of alphanumeric coding, for example, the question of the optimal coding of complex verbal messages, do not yet have such "standard" solutions.
For auditory modality, it is permissible to apply coding based on the categories of timbre, tempo, frequency, loudness, pitch. The coding of qualitative features is quite effectively carried out with the help of timbre, the perception of which is categorical.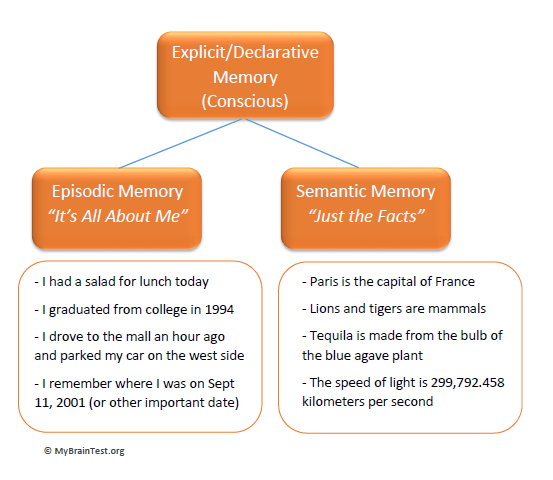 Quantitative features are more efficiently encoded using already height and frequency. Loudness-based coding is rarely used due to fairly obvious practical limitations. When choosing a specific type of audio coding, one must take into account the sound environment of the operator. This is directly related to the various effects of sound overlay, which lead to the so-called masking of sound signals that are significant to the operator.
Quantitative features are more efficiently encoded using already height and frequency. Loudness-based coding is rarely used due to fairly obvious practical limitations. When choosing a specific type of audio coding, one must take into account the sound environment of the operator. This is directly related to the various effects of sound overlay, which lead to the so-called masking of sound signals that are significant to the operator.
The degree of abstractness of the code
The most important criterion when choosing a coding method is the degree of abstractness of the code. A certain code is naturally associated with the content transmitted with its help. Regarding the abstract code, such a connection is rather arbitrary and is determined solely by the convention. The obvious advantage of a certain code is the ease with which the information is decoded (the data is already contained in the sign, which only needs to be found and identified). Coding based on certain codes is quite widely used for visual and audio modality.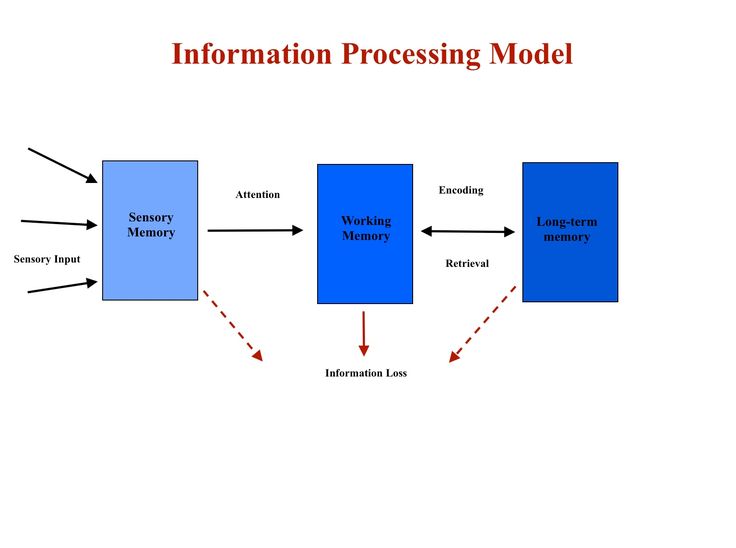
The main advantage of abstract codes is their ability to transmit abstract information, and at the same time a high degree of unambiguity in their interpretation; their noticeable drawback is the need for their preliminary study, as well as regular decoding during operation. When applying both abstract and concrete coding, one should definitely focus on the natural relationships between the values of the displayed indicators and the code characters. For example, an increase in the pitch of an audio signal is generally associated with an increase in temperature. Another significant problem in choosing a particular encoding method is the determination of the optimal length of the alphabet. Its excess in theory increases the amount of transmitted data. For example, decision-relevant information can be transmitted with higher accuracy. But an increase in the length of the code greatly complicates the recognition of signs (distinguishing gradations), and also slows down the processing of information by the individual in general. An alternative way to increase the length of the alphabet is also to increase the dimensionality of the code, that is, the use of signs not of one, but of several different categories.
An alternative way to increase the length of the alphabet is also to increase the dimensionality of the code, that is, the use of signs not of one, but of several different categories.
It turns out that when choosing an alphabet, as well as ways to encode data, one should not only be guided by the available recommendations and expert opinion, but also conduct an empirical assessment of the coding efficiency using operator testing.
Author: Anna Kovrova
Lecturer, Faculty of Psychology, Department of General Psychology. Candidate of Psychological Sciences
Information encoding and decoding - what is it, what is the procedure for, examples of the process, principles, languages and types, unambiguous coding
"Code", "encoding", "decoding" - hearing such words, many people remember films about spy movies. But it turns out that all of the above has long been included in everyday life, and when reading a book or using a computer, a person encodes and decodes information constantly, without thinking about it at all.
But it turns out that all of the above has long been included in everyday life, and when reading a book or using a computer, a person encodes and decodes information constantly, without thinking about it at all.
Necessity of the considered processes
Imagine that a person verbally transmits some data, becoming a source of information. Anyone who hears it will receive the necessary information. And if it is necessary for the computer to “hear” or do you need to save and transfer the data further? This means that it is required to “remake” speech or other information carriers in such a way that it is possible to record or encode , and, if necessary, restore, that is, decode them. Therefore, various algorithms have been developed for the procedure for encoding and decoding transmitted information.
Basic terms and conditions
Coding - presentation of information in a convenient form for processing, storage, transmission.
Decoding is the reverse process, when the data is converted back into a human-readable form.
Code is a package of conditional symbols, thanks to which information is transferred according to established rules.
Mankind has been solving data processing problems since time immemorial. Even in the primitive system, it was necessary to somehow convey various information to their relatives, for example, indicate a place for hunting, tell about the raid of neighbors. Initially, 9 were used for this.0003 drawings, gestures, sound signals - all this can be called "primal code". The recipient, seeing familiar gestures, understood what was at stake, that is, decoded the message.
With the development of society, the languages of peoples and writing began to appear. It became possible to write speech using the alphabet. The letters became a code by which information was stored and transmitted. Knowing the alphabet, you can read the text by decoding it.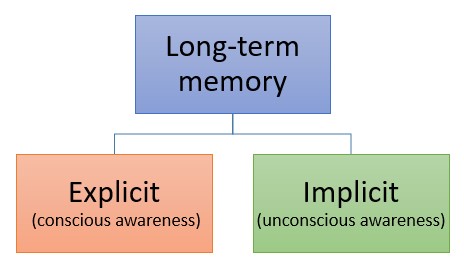 The languages of the peoples of the world are called " natural coding languages ".
The languages of the peoples of the world are called " natural coding languages ".
Unlike them, there are formal , which were invented for ease of use in various sectors of human life. Mathematical signs, musical notes, road signs, the nautical alphabet are examples of formal languages. Writing computer programs will not do without numerous programming languages, which are also formal.
Types and methods of encoding
The choice of the type of encoding is determined by several factors: existing capabilities, circumstances, goals and the likelihood of subsequent data processing. There are 3 types of coding of transmitted document information:
- Letter or symbol . All national alphabets can be attributed to it.
- Graphic . For example, weather forecast, topographic maps or road signs.
- Numeric . Mathematical formulas and calculations, binary code.

Let's explain with examples. One form of encoding is shorthand . Here the conditions or circumstances are such that it is necessary to quickly record the speech of the speaker. Therefore, special code . Using it, a stenographer can write down a whole sentence in a few letters or characters. Here is one example of a transcript:
With mathematical calculations it is convenient to record in the form of numbers. However, if the goal is to accurately write the final number, then it is written in words. Then an accidentally missed digit will not cause distortion of information. So when solving problems at school, they use digital or numeric encoding. But in accounting reports or bank statements write the total amount in letters. It should be noted that the same information was recorded in natural and formal languages. Transitions between them are also encoding.
If it is necessary to hide the content of the document from prying eyes, then encryption is used - one of the types of encoding.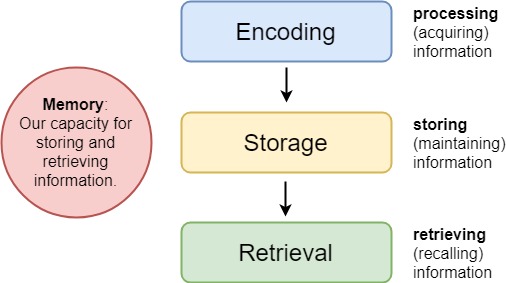 Here, the encoding method is known only to the source and recipient of the data. Decryption of the message is possible with the presence of a key - additional information used in the decryption algorithm. The science of cryptography is engaged in this direction of coding.
Here, the encoding method is known only to the source and recipient of the data. Decryption of the message is possible with the presence of a key - additional information used in the decryption algorithm. The science of cryptography is engaged in this direction of coding.
A brief history of the development of coding
Back in the 2nd century BC. The ancient Greek scholar Polybius used the double torch pattern to represent the letters of the Greek alphabet.
In the 18th century, Claude Chapp designed the semaphore, where each letter had its own figure. The transmission speed of such a device was low: 2 words per minute.
The famous telegraph and Morse code . A truly revolutionary invention of the 19th century. Thanks to three simple characters: dot, dash and pause, it was possible to increase the speed and reliability of coding. The system is still used in navigation today.
Wireless telegraph or radio . In 1895, Popov, and a little later in 1897, Marconi designed a radio receiver separately from each other. Thanks to him, it was possible to use Morse code over long distances.
In 1895, Popov, and a little later in 1897, Marconi designed a radio receiver separately from each other. Thanks to him, it was possible to use Morse code over long distances.
The 20th century was a breakthrough in the field of encoding and decoding information. Cordless telephone, television and radio broadcasting, computer and mobile technologies - data encryption and decryption are used everywhere.
Encoding and decoding various kinds of data
Every day, millions of people use computers without thinking about how text is entered and read. All information is perceived by the computer in digital, binary form , where only 2 characters are used for encoding: 0 and 1, which are called bits. Zero corresponds to low voltage, unit to high. 8 bits form 1 byte.
Modern technologies use several types of information encoding/decoding. We will give an example of the most common methods for encoding and decoding information, which can be considered basic, since there are a lot of types, for example, encoding sound, color, numbers, video, graphics, text, etc.
Numbers and text
Text is encoded using tables ASCII and UNICODE . In them, each character, letter corresponds to a binary code in the form of zeros and ones. ASCII was invented earlier and contains 256 letters and symbols. However, due to the need to encode national alphabets, an extended UNICODE table was compiled. The figure shows the ASCII table:
As can be seen from the table, numbers are also encoded in binary format, arithmetic operations with them are similar to the decimal system. Of course, the final record is very cumbersome, but for computer technology this does not create difficulties. So 4 would be written as 0110100 and 5 would be 0110101. The number 45 would contain both binary codes, but it would be converted to eight-bit binary for calculations.
So 4 would be written as 0110100 and 5 would be 0110101. The number 45 would contain both binary codes, but it would be converted to eight-bit binary for calculations.
Graphics
More bytes are used to encode pictures. Graphic representation is bitmap and vector .
Digital equipment works with individual, discrete parts. Therefore, when creating a bitmap image , the original image is "split" by vertical and horizontal lines into small rectangles - pixels. The more pixels, the better the image quality.
The color of each pixel is set from using three colors : red, green, blue. Such a system is called RGB, where R is red (Red), G is green (Green), B is blue (Blue). When mixing primary colors, you can get almost any shade. The amount of a particular color in one pixel is indicated in binary code. The more bits used for color, the more diverse the color palette of the image, and hence the more realistic the picture.
Vector graphics are used in drawings when ready-made geometric templates are used: rectangle, square, circle and others. Working with it, you only need to specify the location of the object, size and color, you do not need to separately specify the color of each pixel. Vector coding is widely used in publishing and print design.
Sound
A sound wave is characterized by two parameters: amplitude and frequency . Amplitude is responsible for the loudness of the sound, and frequency is responsible for the pitch. Also, sound vibrations are broken into small parts and processed in this form in a digital channel. Each such part corresponds to its own amplitude expressed in binary code. The more details, that is, the more frequency the sound wave breaks, the better the sound encoding occurs.
When decoding, the sound card "collects" all the parts together and delivers analog sound to the speakers.
Numerical information
As already noted, the numbers are encoded by converting them into binary. If you need to convert a fractional number, then 80-bit encryption is used. The disadvantages of the binary representation are the inconvenience when using such a pile of bits and the slowdown in data processing. You can convert the binary system to hexadecimal, which will make it easier to work with numbers.
If you need to convert a fractional number, then 80-bit encryption is used. The disadvantages of the binary representation are the inconvenience when using such a pile of bits and the slowdown in data processing. You can convert the binary system to hexadecimal, which will make it easier to work with numbers.
S. Hall model
The science that studies the structure and functioning of sign systems that are responsible for storage and transmission of information is called semiotics. According to it, when decoding a document, it has the same meaning that was laid down by the encoder or source during the procedure for encoding the transmitted information. Those. unambiguity of encoding/decoding is implied (the message has a single possible interpretation).
S. Hall made adjustments to this representation:
- Sources encrypt texts based on ideological considerations , which means they distort information or manipulate the media.

Learn more