Triggers in recovery
SAMHSA’s National Helpline | SAMHSA
Your browser is not supported
Switch to Chrome, Edge, Firefox or Safari
Main page content
-
SAMHSA’s National Helpline is a free, confidential, 24/7, 365-day-a-year treatment referral and information service (in English and Spanish) for individuals and families facing mental and/or substance use disorders.
Also visit the online treatment locator.
SAMHSA’s National Helpline, 1-800-662-HELP (4357) (also known as the Treatment Referral Routing Service), or TTY: 1-800-487-4889 is a confidential, free, 24-hour-a-day, 365-day-a-year, information service, in English and Spanish, for individuals and family members facing mental and/or substance use disorders.
This service provides referrals to local treatment facilities, support groups, and community-based organizations.
Also visit the online treatment locator, or send your zip code via text message: 435748 (HELP4U) to find help near you. Read more about the HELP4U text messaging service.
The service is open 24/7, 365 days a year.
English and Spanish are available if you select the option to speak with a national representative. Currently, the 435748 (HELP4U) text messaging service is only available in English.
In 2020, the Helpline received 833,598 calls. This is a 27 percent increase from 2019, when the Helpline received a total of 656,953 calls for the year.
The referral service is free of charge. If you have no insurance or are underinsured, we will refer you to your state office, which is responsible for state-funded treatment programs. In addition, we can often refer you to facilities that charge on a sliding fee scale or accept Medicare or Medicaid. If you have health insurance, you are encouraged to contact your insurer for a list of participating health care providers and facilities.
If you have health insurance, you are encouraged to contact your insurer for a list of participating health care providers and facilities.
The service is confidential. We will not ask you for any personal information. We may ask for your zip code or other pertinent geographic information in order to track calls being routed to other offices or to accurately identify the local resources appropriate to your needs.
No, we do not provide counseling. Trained information specialists answer calls, transfer callers to state services or other appropriate intake centers in their states, and connect them with local assistance and support.
-
Suggested Resources
What Is Substance Abuse Treatment? A Booklet for Families
Created for family members of people with alcohol abuse or drug abuse problems. Answers questions about substance abuse, its symptoms, different types of treatment, and recovery. Addresses concerns of children of parents with substance use/abuse problems.
Addresses concerns of children of parents with substance use/abuse problems.It's Not Your Fault (NACoA) (PDF | 12 KB)
Assures teens with parents who abuse alcohol or drugs that, "It's not your fault!" and that they are not alone. Encourages teens to seek emotional support from other adults, school counselors, and youth support groups such as Alateen, and provides a resource list.After an Attempt: A Guide for Taking Care of Your Family Member After Treatment in the Emergency Department
Aids family members in coping with the aftermath of a relative's suicide attempt. Describes the emergency department treatment process, lists questions to ask about follow-up treatment, and describes how to reduce risk and ensure safety at home.Family Therapy Can Help: For People in Recovery From Mental Illness or Addiction
Explores the role of family therapy in recovery from mental illness or substance abuse. Explains how family therapy sessions are run and who conducts them, describes a typical session, and provides information on its effectiveness in recovery.
For additional resources, please visit the SAMHSA Store.
Last Updated: 08/30/2022
Recovery and Recovery Support | SAMHSA
Recovery and Resilience
Resilience refers to an individual’s ability to cope with change and adversity. Resilience develops over time and gives an individual the capacity not only to cope with life’s challenges but also to be better prepared for the next stressful situation. Psychological resilience, the ability to cope with adversity and to adapt to stressful life events, varies widely from person to person and depends on environmental as well as personal factors. It refers to positive adaptation, or the ability to maintain mental and physical health despite participating in stressful situations. Resilience is playing up those protective factors so they can outweigh the risk factors. Optimism and the ability to remain hopeful are essential to resilience and the process of recovery.
Because recovery is a highly individualized process, recovery services and supports must be age appropriate and offered over the life course and flexible enough to ensure cultural relevancy.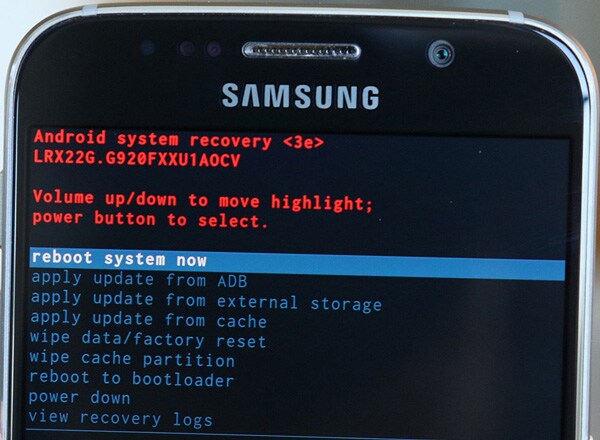 What may work for adults in recovery may be very different for youth or older adults in recovery. For example, the promotion of resiliency in young people, and the nature of social supports, peer mentors, and recovery coaching for adolescents and transitional age youth are different than recovery support services for adults and older adults.
What may work for adults in recovery may be very different for youth or older adults in recovery. For example, the promotion of resiliency in young people, and the nature of social supports, peer mentors, and recovery coaching for adolescents and transitional age youth are different than recovery support services for adults and older adults.
Recovery and Relationships
The process of recovery is supported through relationships and social networks. This often involves family members who become the champions of their loved one’s recovery. They provide essential support to their family member’s journey of recovery and similarly experience the moments of positive healing as well as the difficult challenges. Families of people in recovery may experience adversities in their social, occupational, and financial lives, as well as in their overall quality of family life.
These experiences can lead to increased family stress, guilt, shame, anger, fear, anxiety, loss, grief, and isolation.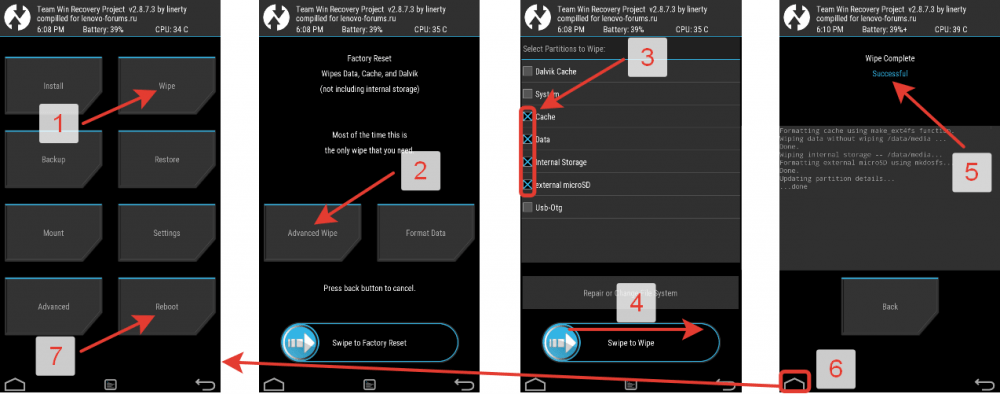 The concept of resilience in recovery is also vital for family members who need access to intentional supports that promote their health and well-being. The support of peers and friends is also crucial in engaging and supporting individuals in recovery.
The concept of resilience in recovery is also vital for family members who need access to intentional supports that promote their health and well-being. The support of peers and friends is also crucial in engaging and supporting individuals in recovery.
Peer support assists individuals to engage or stay connected to the recovery process through a shared understanding, respect, and mutual empowerment. Peer support extends beyond the reach of clinical treatment into the everyday environment providing non-clinical, strengths-based support. This relationship can help lay the foundation for SAMHSA’s four dimensions of recovery.
Recovery Support
SAMHSA advanced recovery support systems to promote partnering with people in recovery from mental and substance use disorders and their family members to guide the behavioral health system and promote individual, program, and system-level approaches that foster health and resilience; increase housing to support recovery; reduce barriers to employment, education, and other life goals; and secure necessary social supports in their chosen community.
Recovery support is provided in various settings. Recovery support services help people enter into and navigate systems of care, remove barriers to recovery, stay engaged in the recovery process, and live full lives in communities of their choice.
Recovery support services include culturally and linguistically appropriate services that assist individuals and families working toward recovery from mental and/or substance use problems. They incorporate a full range of social, legal, and other services (PDF | 409 KB). that facilitate recovery, wellness, and linkage to and coordination among service providers, and other supports shown to improve quality of life for people (and their families) in and seeking recovery.
Recovery support services may be provided before, during, or after clinical treatment, or may be provided to individuals who are not in treatment but seek support services.
These services, provided by professionals and peers, are delivered through a variety of community and faith-based groups, treatment providers, schools, and other specialized services. The broad range of service delivery options ensures the life experiences of all people are valued and represented.
The broad range of service delivery options ensures the life experiences of all people are valued and represented.
For example, in the United States there are 34 recovery high schools that help reduce the risk in high school environments for youth with substance use disorders. These schools typically have high retention rates and low rates of students returning to substance use.
Additionally, SAMHSA's Bringing Recovery Supports to Scale Technical Assistance Center Strategy (BRSS TACS) advances effective recovery supports and services for people with mental or substance use disorders and their families.
Find more Publications and Resources on Recovery and Recovery Support.
Implementing Disaster Recovery / Sudo Null IT News
Hello everyone, my name is Sergey Burladyan, I work at Avito as a database administrator. I work with the following systems:
This is our central base 2 TB, 4 servers - 1 master, 3 standby. We also have londiste-based logical replication (this is from Skytools), an external sphinx index, various uploads to external systems - such as DWH, for example. We also have our own developments in the field of remote procedure call, the so-called xrpc. Storage for 16 bases. And another figure is that our backup takes 6 hours, and its restoration takes about 12. I would like that in the event of various failures of these systems, our site downtime would take no more than 10 minutes. nine0002
We also have our own developments in the field of remote procedure call, the so-called xrpc. Storage for 16 bases. And another figure is that our backup takes 6 hours, and its restoration takes about 12. I would like that in the event of various failures of these systems, our site downtime would take no more than 10 minutes. nine0002
If you try to imagine the various connections of these systems, they somehow look like this:
And how not to lose all this in an accident?
What kind of accidents can happen?
I'm looking at mostly server loss crashes, plus for the master there could be another crash like a data explosion.
Let's start.
Let's say some administrator mistakenly made an update without where. We have had this happen several times. How to protect yourself from it? We protect ourselves by having a standby that applies WALs with a 12 hour delay. When such an accident occurred, we took this data from standby and uploaded it back to master. nine0004
nine0004
The second failure that can happen to the master is the loss of the server. We use asynchronous replication and after the loss of the server, we must promote some kind of standby. And since Since we have asynchronous replication, it is necessary to perform various other procedures to restore related systems. Our master is central and is a data source, respectively, if it switches, and replication is asynchronous, then we lose part of the transactions, and it turns out that part of the system is in an unattainable future for the new master. nine0004
It's hard to do it by hand, so you need to do it right away with a script. What does an accident look like? In external systems, declarations appear that are no longer on the master, sphinx gives out non-existent declarations when searching, sequences jumped back, logical replicas, in particular, because of this, also stopped working (londiste).
But not everything is so bad, it's all possible to restore.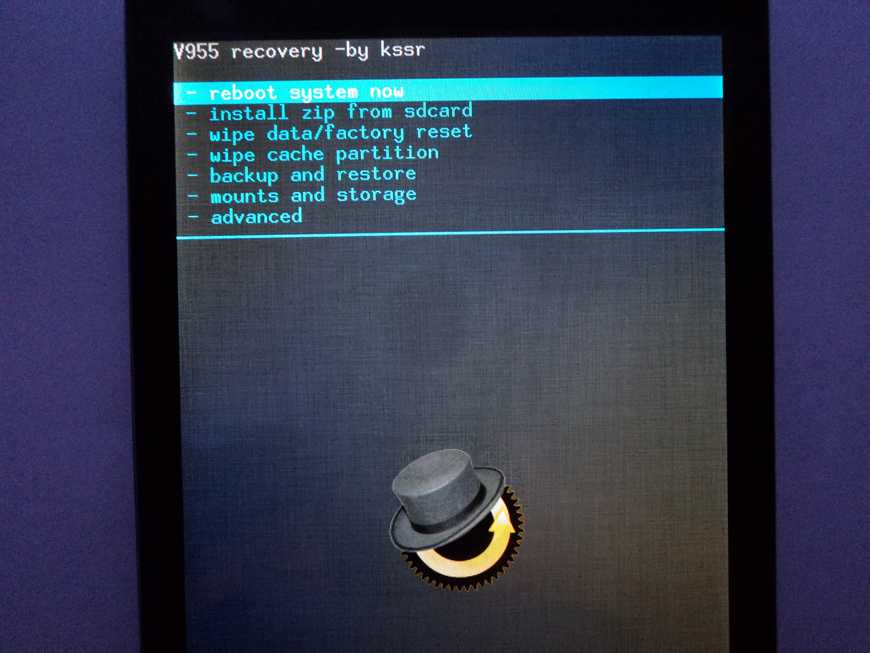 We sat, thought and planned the recovery procedure. In particular, we can simply unload DWH again. And directly, because we have a simple 10 minutes, then on monthly reports the change in these lost items is simply not visible. nine0004
We sat, thought and planned the recovery procedure. In particular, we can simply unload DWH again. And directly, because we have a simple 10 minutes, then on monthly reports the change in these lost items is simply not visible. nine0004
How to repair xrpc? We use xrpc for geocoding, for calling asynchronous procedures on the master, and for calculating user karma. Accordingly, if we have geocoded something, i.e. from the address they turned it into coordinates on the map, and then this address disappeared, then it’s okay that it remains geocoded, it’s just that we won’t geocode the same address the second time, so there’s no need to restore anything. A local procedure call is asynchronous, because it is local, it is located on the same base server, even on the same base, and therefore, when we switched the base, it is consistent. You don't need to restore anything either. User karma. We decided that if a user did something bad, and then an accident occurred, and we lost these bad items, then the user's karma can not be restored either.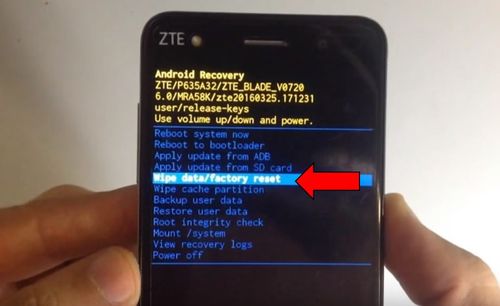 He did these bad things, let them stay with him. nine0004
He did these bad things, let them stay with him. nine0004
Sphinx site. We have two sphinx - one for the site, the other for the backoffice. Sphinx, which is a site, is implemented in such a way that it completely rebuilds its entire index every 10 minutes. Accordingly, an accident occurred, recovered, and after 10 minutes the index is completely rebuilt and corresponds to the master. And for the backoffice, we decided that it’s also not critical, we can refresh some of the ads that have changed after the restoration, and plus once a month we completely rebuild the entire sphinx backoffice, and all these emergency items will be cleaned. nine0004
How to restore sequences so they don't jump back? We just chose sequences that are important for us, such as item_id, user_id, payment primary key, and after the accident we scroll them forward by 100 thousand (we decided that it would be enough for us).
We restore logical replication with our system, this is a patch for londiste that makes UNDO for logical replica.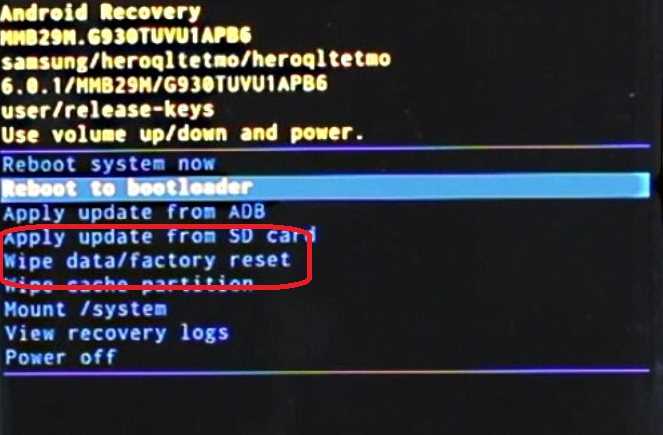
The Undo patch is these three commands. The command itself and plus two Undo add/remove commands for the logical replica. And we also added a flag to replay in londiste so that it passes the TICK_ID from the master to the Postgres session variable. nine0004
it is implemented - it's just triggers on all tables of the subscriber. The trigger writes to the history table what operation actually took place. in the target table. It remembers this passed tick_id with the master in this record. Accordingly, when the accident occurred, the logical replica was in the future, and it needs to be cleaned up in order to restore changes that are from an unreachable future. This is done by executing reverse queries, i.e. for insert we do delete, for update we update with previous values, well, for delete we do insert. nine0004
We don't do it all by hand, we do it with the help of a script. What is the feature of our script here? We have three asynchronous standby, respectively, before switching, we need to find out which one is closest to the master. Next, we select this standby, wait until it plays the remaining WALs from the archive, and select it for the future master. Next, we are using Postgres 9.2. The peculiarity of this version is that in order for standby to switch to a new promotion and master, they have to be stopped. Supposedly at 9.4 this can no longer be done. Accordingly, we do promote, move sequences forward, execute our Undo procedure, start standby. And then here is also an interesting point - you need to wait until standby connects to the new master. We do this by waiting for the new master timeline to appear on the appropriate standby.
Next, we select this standby, wait until it plays the remaining WALs from the archive, and select it for the future master. Next, we are using Postgres 9.2. The peculiarity of this version is that in order for standby to switch to a new promotion and master, they have to be stopped. Supposedly at 9.4 this can no longer be done. Accordingly, we do promote, move sequences forward, execute our Undo procedure, start standby. And then here is also an interesting point - you need to wait until standby connects to the new master. We do this by waiting for the new master timeline to appear on the appropriate standby.
And it turns out that there is no such SQL function in Postgres, it is impossible to understand the timeline on standby. But we solve it in this way, it turns out that you can connect via the Postgres replication protocol to standby, and there, after the first command, standby will report its timeline highlighted in red. nine0004
This is our master recovery script.
Let's go further. How do we recover directly when some external systems fall apart. For example standby. Because we have three standby, as I said, we just take, switch to the remaining standby if one of them falls. As a last resort, even if we lose all standby, we can switch traffic to the master. Some of the traffic will be lost here, but, in principle, the site will work. There was still such a trick here - at first I kept creating new standby from backup, then we got SSD’s servers, and I still continued to restore standby from backup. Then it turned out that if you take it from a backup, the recovery takes 12 hours, and if you just take pg_basebackup from some working standby, then it takes much less time. If you have several standby, you can try to check it with you. nine0004
If the site's sphinx breaks. The site sphinx is written in such a way that it completely rebuilds the entire index, and the site sphinx is all active site ads. Now all 30 or 35 million ads on the site are indexed by this system.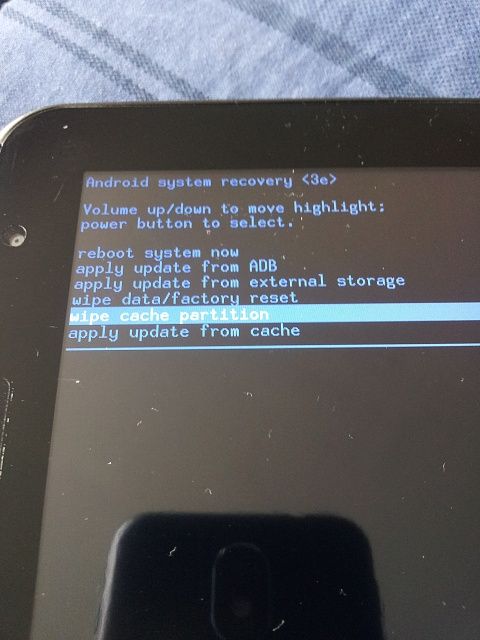 Indexing comes from a separate logical replica, it is prepared specifically for indexing and is made in such a way that everything is laid out in memory there, and indexing takes place very quickly, so we can do indexing every 10 minutes, completely from scratch. We have a pair of logical replicas. And if we lose a replica, we switch to its reserve. And if something happened to sphinx, then in 10 minutes it will be completely reindexed, and everything will be fine. nine0004
Indexing comes from a separate logical replica, it is prepared specifically for indexing and is made in such a way that everything is laid out in memory there, and indexing takes place very quickly, so we can do indexing every 10 minutes, completely from scratch. We have a pair of logical replicas. And if we lose a replica, we switch to its reserve. And if something happened to sphinx, then in 10 minutes it will be completely reindexed, and everything will be fine. nine0004
How can I restore export to DWH? Suppose we exported something, an accident occurred on DWH, we lost some of the latest data. Our DWH export goes through a separate logical replica, and the last four days are stored on this replica. We can simply call the export script again with our hands and unload all this data. Plus there is still an archive of six months. Or, as a last resort, because we have several standbys, we can take one of them, pause it and re-upload, in general, all the data from the master in DWH.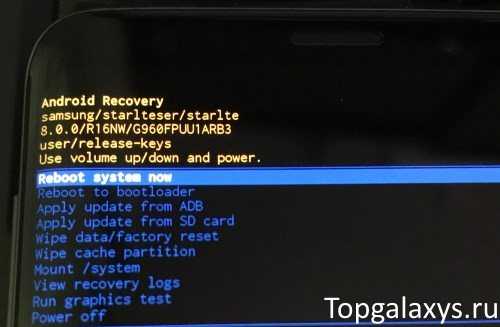 nine0004
nine0004
Xrpc is implemented on top of pgq (this is Skytools), and thanks to this we can do such tricky things. Pgq is, in fact, just a table in the database, events are stored in it. It looks exactly like the one in the picture. There is an event time and transaction id. When we have restored the xrpc client, we can move back in this queue and replay those events that are not in the receiver.
Xdb - we have a repository of several databases. 16 bases are located on eight machines. We reserve this storage in the following way - it's just that Postgres binary replication is configured from one machine to another. Those. the first machine is reserved by standby on the second, the second on the third, respectively, the eighth on the first. In addition, playing WALs, there is also a delay of four days, i.e., in fact, we have a four-day backup of any of these nodes. nine0004
Now I will tell you in detail about the replica, what it is. We have built a logical replica based on Postgres capabilities, this is a view on the master and a deferred trigger on the necessary tables. These triggers trigger a special function that writes to a separate table. It can be thought of as a materialized representation. And then this plate is replicated by means of londiste to a logical turnip.
These triggers trigger a special function that writes to a separate table. It can be thought of as a materialized representation. And then this plate is replicated by means of londiste to a logical turnip.
Directly, it somehow looks like this, I will not dwell on this in detail. nine0004
And the logical replica server itself, why is it needed at all? This is a separate server. It is characterized by the fact that everything is in memory there, i.e. shared_buffers of such a size that the whole table and its indexes fit completely into it. This allows such logical replicas to serve a large load, in particular, for example, one turnip serves 7000 transactions per second, and 1000 events are queued from the master to it. Because this is a logical replica implemented using londiste and pgq, so there is a handy thing there - tracking which transactions have already lost on this logical replica. And based on this thing, you can do things like Undo. nine0004
I already said that we have two replicas, we can recover by simply switching.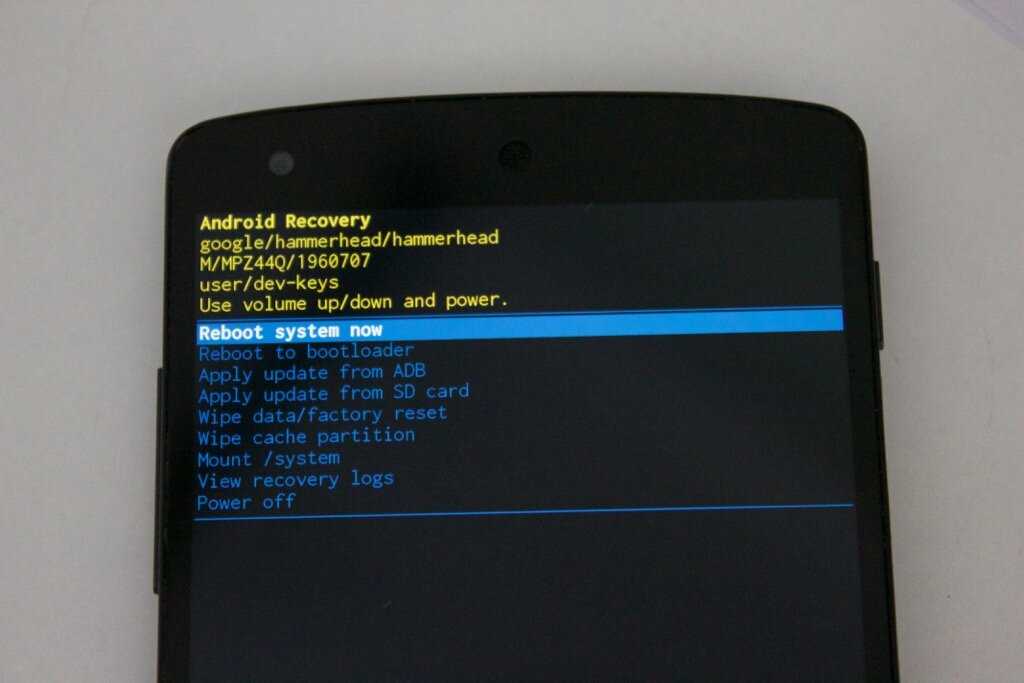 If one replica is lost, we switch to the second. This is possible because pgq allows multiple consumers to subscribe to the same queue. The turnip has fallen, and then we need to restore its copy. If this is done simply by means of londiste, then it now takes us 4 hours for the turnip of the site, and 8 hours for the sphinx, because triggers are called there, which cut the data for convenient indexing to the sphinx, and this is all very long. But it turned out that there is another way to create a fallen turnip - you can make a pg_dump with a working one. nine0004
If one replica is lost, we switch to the second. This is possible because pgq allows multiple consumers to subscribe to the same queue. The turnip has fallen, and then we need to restore its copy. If this is done simply by means of londiste, then it now takes us 4 hours for the turnip of the site, and 8 hours for the sphinx, because triggers are called there, which cut the data for convenient indexing to the sphinx, and this is all very long. But it turned out that there is another way to create a fallen turnip - you can make a pg_dump with a working one. nine0004
But if you just pg_dump and run londiste on it, it won't work, because londiste keeps track of the current position of the lost transaction both on the master and on the logical replica. So there are still more steps to be taken. It needs to be corrected after restoring the dump on the master tick_id so that it matches the tick_id that is on the restored turnip. If so, copy through pg_dump, then all this takes no more than 15 minutes.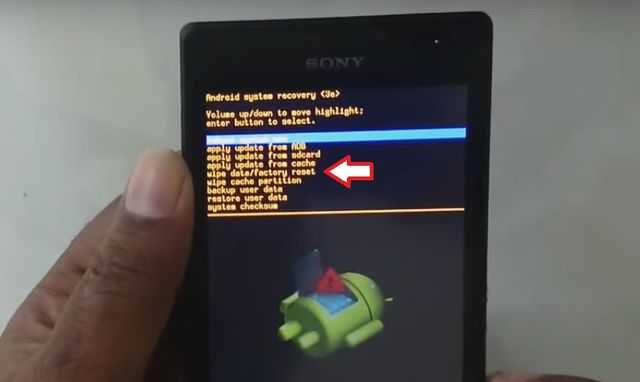
The algorithm itself somehow looks like this.
Backup is designed to protect against accidents, but accidents can also occur directly with the backup itself. For example, in the Postgres WAL archiving command, it doesn't specify what fsync should do when WAL is written to an archive. But this is an important thing and allows you to protect yourself from, say, an emergency reload of the archive. In addition, our backup is also backed up by the fact that it is copied to an external cloud. But in the plans: we want to make two active archive servers so that archive_command writes to both WALs. You can also say that at first we experimented with pg_receivexlog in order to receive directly on the WAL archive servers themselves, but it turned out that in 9.2 it's almost impossible to use because it doesn't fsync, it doesn't keep track of which WALs it has already received from the master, which can be cleared at checkpoint. Now Postgres has done it. And, perhaps, in the future we will use not archive_command, but pg_receivexlog after all.
We do not use streaming at home. Those. what I was talking about is all based only on the WAL archive. This was done due to the fact that it is difficult to provide an archive when streaming, as well. if, for example, we take an archive from standby, the backup has ended, and the master has not yet managed to archive all these WALs needed to restore the backup. And we get a broken backup. This can be bypassed if, for example, our standby, from which we take the backup, is 12 hours behind, like ours. Or - in Postgres 9.5 made the archive_mode=always setting such that there would be no such problem. It will be possible to take a backup from standby and get WALs directly from standby to the archive.
It is not enough to just make a backup, you still need to check whether everything is backed up correctly. We do this on a test server, and for this we wrote a special backup verification script. It is based on what it checks after the server is restored and the error message is triggered in the server log.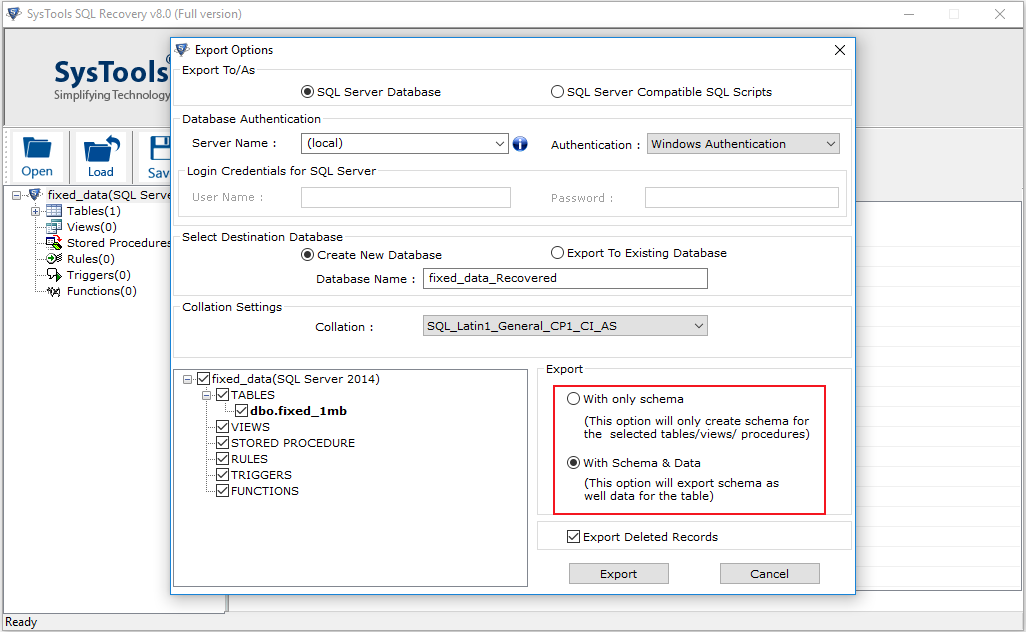 And for each database restored on the cluster, a special checking function check_backup is called, which performs additional checks. In particular, such a check that the date of the last transaction should differ from the date of the last announcement by no more than a minute. Those. if there are no holes, we consider that the backup was restored correctly. nine0004
And for each database restored on the cluster, a special checking function check_backup is called, which performs additional checks. In particular, such a check that the date of the last transaction should differ from the date of the last announcement by no more than a minute. Those. if there are no holes, we consider that the backup was restored correctly. nine0004
On the slides you can see what specific errors we analyze in the log when checking the backup.
Previously, we checked backups by vacuuming the entire database and subtracting tables, but then we decided to abandon this, because we count more reports from the restored backup, and if the reports were calculated correctly, there are no holes, strange values, then the backup done correctly.
I talked about asynchronous replication, but sometimes you want to make it synchronous. Our Avito consists of many services, one of these services is a payment service. And due to the fact that it is allocated, we can make synchronous replication for it, because he works on a separate base.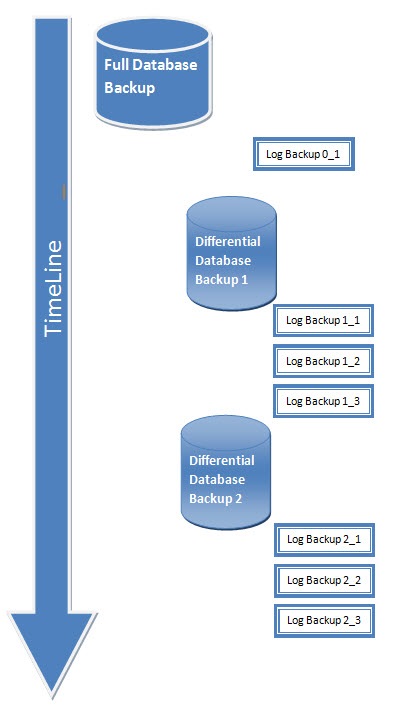 There is not such a big load and the standard network latency allows us to enable synchronous replication there. nine0004
There is not such a big load and the standard network latency allows us to enable synchronous replication there. nine0004
What can be said at the end? Still, despite the fact that replication is synchronous, you can work and recover in this mode, if you look at your connected systems, you can figure out how to restore them. It is also important to test backups.
Another remark. We have a recovery script, at the end of it you need to change the DNS's, because. we have a master or a slave - this is fixed in the DNS. We're currently thinking about using some kind of system like ZooKeeper to automatically switch DNS. Such plans. nine0004
This talk is a transcript of one of the best talks at the HighLoad++ Developers Conference. Now we are actively preparing the 2016 conference - this year HighLoad++ will be held in Skolkovo on November 7 and 8.The Avito team traditionally offers very strong performances, for example, this year it will be:
- Migration experience between data centers / Mikhail Tyurin
- Sphinx 3.
0 and RT indexes on the main Avito search / Andrey Smirnov, Vyacheslav Kryukov; nine0147
Also, some of these materials are used by us in the online training course on the development of high-load systems HighLoad.Guide is a chain of specially selected letters, articles, materials, videos. There are already more than 30 unique materials in our textbook. Connect!
Restoration of triggers in a closed map. Part 1 - Articles - Warcraft 3 / Modding
Hello everyone, today I will teach you how to restore triggers in closed maps. Tell me why, if you can just take, hack a card and leave one trigger, which is full of a bunch of other triggers in text form? If you hack a map to insert a cheat, then you don't need it... But if you find a map that is outdated, it's cool, and the author of the map doesn't want to give the source code, or just lost it a long time ago, or maybe Warcraft just abandoned it.. The first thing that comes to mind is hacking the card. So you hack the map, open the triggers and? See, all triggers are text! Perhaps this is not a problem for you, you just leave those triggers alone and add your own, but what if you need to radically rewrite half of the code due to its buggy? Then you should completely rewrite the code . .. And if there is a lot of work there? Or is there something you can't do? You will most likely just throw the card aside... And continue working on the old project or start a new one... So, for those who have been in such a situation or "want" to get into it, I am writing this article. nine0004
.. And if there is a lot of work there? Or is there something you can't do? You will most likely just throw the card aside... And continue working on the old project or start a new one... So, for those who have been in such a situation or "want" to get into it, I am writing this article. nine0004
I will say that article is intended for people who know the basics of Jass!
Let's start with a simple one: Let's take a card and hack it, I won't describe the hacking methods, because the article describes how to restore triggers from a card that was closed in the simplest way: - by deleting the trigger file!
As for the fact that now everyone is not just deleting triggers, but will also leak completely, I will tell you in the next article, a simple option will be dealt with here, I advise you to start your "career" of a cracker with it ...
And for "easy" hacking of the map, that is, restoring triggers, you need to use JNGP.
So, we open triggers, that is, "one" trigger, the most important for us.
The first thing to do, of course, with this assembly of triggers is optimization!
Just because the person who decides that deleting the trigger file from the map will be enough for the map not to be "copied-pasted", the person is clearly new to jass, and probably only used triggers in his map.
I know there are articles on this topic, but here the optimization is a little different... nine0004
function Trig_Game_End_Dbl_Chk_Func002002001 takes nothing returns boolean return(IsUnitAliveBJ(GetEnumUnit())) end function function Trig_Game_End_Dbl_Chk takes nothing returns nothing if(Trig_Game_End_Dbl_Chk_Func002002001())then set udg_boolean01=false endif endfunction
Everyone who uses triggers gets something like this when translated into code.
The first thing to do is to copy everything that is in the return brackets and move it into the if brackets. nine0002 As a result, you should get the following:
function Trig_Game_End_Dbl_Chk takes nothing returns nothing if IsUnitAliveBJ(GetEnumUnit()) then set udg_boolean01=false endif endfunction
Don't forget to remove the first function as we don't need it anymore.
Most lines of code will be like this! So this is the first and important step, otherwise it will just be more difficult to work with the code further ...
- You will often see the following:
function Trig_sssss_Conditions takes nothing returns boolean if ( not ( IsUnitType(GetTriggerUnit(), UNIT_TYPE_STRUCTURE) == true ) ) then return false endif return true endfunction
Do this with this construct:
function Trig_ssss_Conditions takes nothing returns boolean return IsUnitType(GetTriggerUnit(), UNIT_TYPE_STRUCTURE) == true end function
You can also shorten it like this:
function Trig_ssss_Conditions takes nothing returns boolean return IsUnitType(GetTriggerUnit(), UNIT_TYPE_STRUCTURE) endfunction
Removing == true, since one boolean is being compared with another, which is stupid. ..
..
But what if instead of true - false ??
Like this:
function Trig_ssss_Conditions takes nothing returns boolean return not IsUnitType(GetTriggerUnit(), UNIT_TYPE_STRUCTURE) end function
adding not at the beginning.
- Design repeat:
function Trig_Remove_A takes nothing returns boolean return(GetPlayerSlotState(GetFilterPlayer())==PLAYER_SLOT_STATE_PLAYING) end function function Trig_Remove_Func001002 takes nothing returns nothing if GetPlayerColor(GetEnumPlayer())==PLAYER_COLOR_RED then set udg_strings01[(1+GetPlayerId(GetEnumPlayer()))]="|cffff0800" endif end function ... call ForForce(GetPlayersMatching(Condition(function Trig_Remove_A)),function Trig_Remove_Func001002) call ForForce(GetPlayersMatching(Condition(function Trig_Remove_A)),function Trig_Remove_Func002002) ... nine0174There can be many of these checks whether the player is playing or similar.
Here I have already optimized, in choosing a group. These conditions can be repeated many times, it is easier to just leave one condition and substitute this condition in all group selections. The main thing is to try to leave these conditions in the conditional place of the trigger, that is, within the framework of the future trigger, so that it is easier to determine what the check is checking ... I replace it with a local one. nine0147
call EnableTrigger( udg_trigger01 ) call DisableTrigger( udg_trigger01 ) call ConditionalTriggerExecute( udg_trigger01 ) call TriggerExecute( udg_trigger01 ) call QueuedTriggerAddBJ( udg_trigger01, true ) call QueuedTriggerRemoveBJ( udg_trigger01 ) call TriggerRegisterGameStateEventTimeOfDay( udg_trigger01, EQUAL, 12 )
These functions may be present in the code:
These functions perform various actions with triggers, in the code they will be designated as global variables udg_triggerXX. nine0002 The first thing to do is to find all these function calls in the code.
See what trigger is used there, well, the name of the trigger variable. I have this udg_trigger01
Enter the name of the trigger in the search, and delve into the "deep" function Main2 (this is a large function that initiates everything that is in the map...)
set udg_trigger01=CreateTrigger() call TriggerRegisterAnyUnitEventBJ(udg_trigger01,EVENT_PLAYER_UNIT_DEATH) call TriggerAddCondition(udg_trigger01,Condition(function Trig_Bobdies_Conditions)) call TriggerAddAction(udg_trigger01,function Trig_Bobdies_Actions)
we find something like this.
We see the name of the function, I have this: Bobdies
We take and copy this name. We go to the top, to the call of this trigger through its variable.
Replace udg_trigger01 with: gg_trg_Bobdies
This is not absolutely necessary, but it is necessary for those who do not want TriggerXX to hang in the list of global variables.
The first thing we need to do is create folders, create as many folders as there are triggers/20, I determined this figure for myself, well, so that 1 folder contains 20 triggers. I especially note that it is better to leave all the triggers in the exact order in which they are ... Until the full recovery. nine0002 We take, we are looking for a variable in the code: udg_trigger01
I especially note that it is better to leave all the triggers in the exact order in which they are ... Until the full recovery. nine0002 We take, we are looking for a variable in the code: udg_trigger01
We stumble again deep into the main2 function
Copy the following lines:
set udg_trigger01=CreateTrigger() call TriggerRegisterAnyUnitEventBJ(udg_trigger01,EVENT_PLAYER_UNIT_DEATH) call TriggerAddCondition(udg_trigger01,Condition(function Trig_Bobdies_Conditions)) call TriggerAddAction(udg_trigger01,function Trig_Bobdies_Actions)
Well, or a little bit different, each trigger has its own strings. Not every trigger has the same events...
Create a new trigger. Convert trigger to text. Delete everything in this trigger.
Paste what we copied.
And we call our trigger like this: as the function is named, I call it Bobdies.
Now back to the code, delete the lines that we copied.
And we are looking for the next function, I have it - Trig_Bobdies
We are looking for and copying everything related to this function!
We paste all this into the trigger that we created earlier. (Paste this above what you copied earlier.)
(Paste this above what you copied earlier.)
And delete, from the original trigger, what we copied.
Voila, we've pulled the first trigger.
The following triggers are pulled out by analogy.
I will say, one thing, that for 75 triggers, I spent 2 hours.
And that's all now, if you did everything correctly, then you should have the following functions in the original trigger:
function main2
and other functions responsible for the name of the map, units on the map ...
We do not touch them, so we leave them.
(If you are absolutely sure that main2 is a COMPLETE copy of main , feel free to delete it) Main can be seen by opening the .J map. nine0159
Well, you have restored all the triggers, and now you need to eliminate all the errors associated with the restoration!
They are, believe me!
Save your map with Jasshelper included.
And fix the errors that appear. I will not talk about their elimination, due to the fact that so much has been written about them.
Checked everything, no errors! The first thing to do is to check if the card starts at all? Yes, it happens that it does not start, in which case you will have to check all triggers for errors manually ...
But, if the card is starting up for you, and everything is normal, then you need to check whether the card is working correctly, in many cases, it happens that during optimization, you can break a couple of triggers, but this can be easily fixed in view of the fact that you will be fine know which trigger is responsible for what and fix it.
Now the card works, everything is as in the original. It remains only to do the following:
Disband all triggers according to the "correct" folders. It's as you wish.
And if you want to continue the development of the map, then you must also do the following:
Optimize BJ functions, or replace them in vain. I will not talk about this in detail, since there is already an article on this subject. And yes, it's not entirely mandatory.